微博先锋:Twitter系统结构分析
【6】流量洪峰与云计算
上一篇历数了一则短信从发表到被阅读,Twitter业务逻辑所经历的6个步骤。表面上看似乎很乏味,但是细细咀嚼,把每个步骤展开来说,都有一段故事。
美国年度橄榄球决赛,绰号超级碗(Super Bowl)。Super Bowl在美国的收视率,相当于中国的央视春节晚会。2008年2月3日,星期天,该年度Super Bowl如期举行。纽约巨人队(Giants),对阵波士顿爱国者队(Patriots)。这是两支实力相当的球队,决赛结果难以预料。比赛吸引了近一亿美国人观看电视实况转播。
对于Twitter来说,可以预料的是,比赛进行过程中,Twitter流量必然大涨。比赛越激烈,流量越高涨。Twitter无法预料的是,流量究竟会涨到多少,尤其是洪峰时段,流量会达到多少。
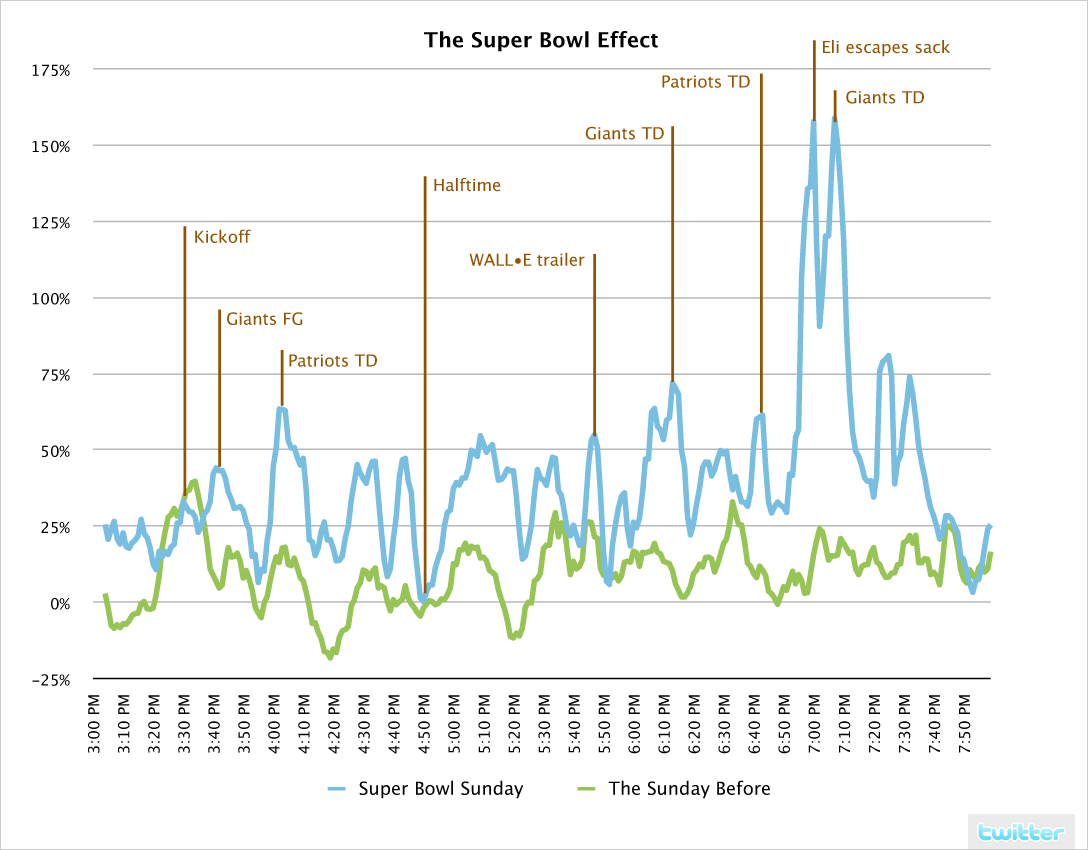
根据[31]的统计,在Super Bowl比赛进行中,每分钟的流量与当日平均流量相比,平均高出40%。在比赛最激烈时,更高达150%以上。与一周前,2008年1月27日,一个平静的星期天的同一时段相比,流量的波动从平均10%,上涨到40%,最高波动从35%,上涨到150%以上。

Figure 8. Twitter traffic during Super Bowl, Sunday, Feb 3, 2008 [31]. The blue line represents the percentage of updates per minute during the Super Bowl normalized to the average number of updates per minute during the rest of the day, with spikes annotated to show what people were twittering about. The green line represents the traffic of a “regular” Sunday, Jan 27, 2008.
Courtesy http://farm3.static.flickr.com/2770/4085122087_970072e518_o.png
由此可见,Twitter流量的波动十分可观。对于Twitter公司来说,如果预先购置足够的设备,以承受流量的变化,尤其是重大事件导致的洪峰流量,那么这些设备在大部分时间处于闲置状态,非常不经济。但是如果缺乏足够的设备,那么面对重大事件,Twitter系统有可能崩溃,造成的后果是用户流失。
怎么办?办法是变买为租。Twitter公司自己购置的设备,其规模以应付无重大事件时的流量压力为限。同时租赁云计算平台公司的设备,以应付重大事件来临时的洪峰流量。租赁云计算的好处是,计算资源实时分配,需求高的时候,自动分配更多计算资源。
Twitter公司在2008年以前,一直租赁Joyent公司的云计算平台。在2008年2月3日的Super Bowl即将来临之际,Joyent答应Twitter,在比赛期间免费提供额外的计算资源,以应付洪峰流量[32]。但是诡异的是,离大赛只剩下不到4天,Twitter公司突然于1月30日晚10时,停止使用Joyent的云计算平台,转而投奔Netcraft [33,34]。
Twitter弃Joyent,投Netcraft,其背后的原因是商务纠葛,还是担心Joyent的服务不可靠,至今仍然是个谜。
变买为租,应对洪峰,这是一个不错的思路。但是租来的计算资源怎么用,又是一个大问题。查看一下[35],不难发现Twitter把租赁来的计算资源,大部分用于增加Apache Web Server,而Apache是Twitter整个系统的最前沿的环节。
为什么Twitter很少把租赁来的计算资源,分配给Mongrel Rails Server,MemCached Servers,Varnish HTTP Accelerators等等其它环节?在回答这个问题以前,我们先复习一下前一章“数据流与控制流”的末尾,Twitter从写到读的6个步骤。
这6个步骤的前2步说到,每个访问Twitter网站的浏览器,都与网站保持长连接。目的是一旦有人发表新的短信,Twitter网站在500ms以内,把新短信push给他的读者。问题是在没有更新的时候,每个长连接占用一个Apache的进程,而这个进程处于空循环。所以,绝大多数Apache进程,在绝大多数时间里,处于空循环,因此占用了大量资源。
事实上,通过Apache Web Servers的流量,虽然只占Twitter总流量的10%-20%,但是Apache却占用了Twitter整个服务器集群的50%的资源[16]。所以,从旁观者角度来看,Twitter将来势必罢黜Apache。但是目前,当Twitter分配计算资源时,迫不得已,只能优先保证Apache的需求。
迫不得已只是一方面的原因,另一方面,也表明Twitter的工程师们,对其系统中的其它环节,太有信心了。
在第四章“抗洪需要隔离”中,我们曾经打过一个比方,“在晚餐高峰时段,餐馆常常客满。对于新来的顾客,餐馆服务员不是拒之门外,而是让这些顾客在休息厅等待”。对于Twitter系统来说,Apache充当的角色就是休息厅。只要休息厅足够大,就能暂时稳住用户,换句行话讲,就是不让用户收到HTTP-503的错误提示。
稳住用户以后,接下去的工作是高效率地提供服务。高效率的服务,体现在Twitter业务流程6个步骤中的后4步。为什么Twitter对这4步这么有信心?
Reference,
[16] Updating Twitter without service disruptions.
(http://gojko.net/2009/03/16/qcon-london-2009-upgrading-twitter-without-service-disruptions/)
[30] Giants and Patriots draws 97.5 million US audience to the Super Bowl. (http://www.reuters.com/article/topNews/idUSN0420266320080204)
[31] Twitter traffic during Super Bowl 2008.
(http://blog.twitter.com/2008/02/highlights-from-superbowl-sunday.html)
[32] Joyent provides Twitter free extra capacity during the Super Bowl 2008.
(http://blog.twitter.com/2008/01/happy-happy-joyent.html)
[33] Twitter stopped using Joyent’s cloud at 10PM, Jan 30, 2008. (http://www.joyent.com/joyeurblog/2008/01/31/twitter-and-joyent-update/)
[34] The hasty divorce for Twitter and Joyent.
(http://www.datacenterknowledge.com/archives/2008/01/31/hasty-divorce-for-twitter-joyent/)
[35] The usage of Netcraft by Twitter.
(http://toolbar.netcraft.com/site_report?url=http://twitter.com)


{kind=link}